В общении Терри поразительно раскован: кажется, он говорит все, что думает, и, хотя порой случаются неловкие моменты, это нисколько его не смущает. К тому же у него замечательный гогочущий смех, который слышен издалека. На кафедре нейробиологии не знали, что делать с Терри. В соавторстве с Куффлером он опубликовал интересную и ныне забытую статью о синаптической передаче в простой модели нервной системы. Но эмпирические подходы, культивировавшиеся на кафедре нейробиологии, все же остались для Терри чужими.
После Гарварда Сейновски получил место преподавателя в Университете Джонса Хопкинса и примерно в то же время познакомился с Джеффри Хинтоном, который вместе с Дэвидом Румельхартом и другими изобрел метод обратного распространения ошибки. Этот метод, как мы уже знаем, играет решающую роль в обучении нейронной сети, позволяя уточнять значения синаптических весов в обратном направлении, от выхода через все скрытые слои к входному слою. Сейновски позаимствовал этот замечательный инструмент, чтобы использовать его в своей лаборатории.
Трудясь на поприще клеточной нейробиологии, я ничего не слышал о Терри в начале 1980-х гг. Но в 1985-м я посетил его лабораторию, где он продемонстрировал мне нейронную сеть, которая сама научилась говорить. Я был потрясен.
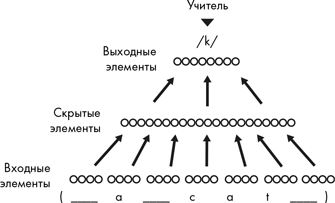
В нейросеть вводились буквы, по одной за раз. Например, исследователи просили сеть произнести букву
Почему эта задача вызывает особый интерес? Потому что английский язык славится своим вариативным произношением, мало подчиняющимся правилам (об этом хорошо знают все иностранцы, которые пытаются его изучать). Например, у нас есть правило, что гласные становятся долгими, если на конце слова есть буква
К счастью, они также составили словарь транскрипций, содержащий 20 000 английских слов с их стандартным произношением. Именно этот словарь Терри Сейновски и Чарльз Розенберг использовали в качестве «учителя» для своей нейронной сети. После того как сеть выдавала свой вариант произношения буквы
Чтобы сделать работу нейросети доступной для внешних наблюдателей, Сейновски и Розенберг (весьма разумно) подключили ее к «диктору» – компьютерной программе, которая преобразует транскрибированные английские фонемы и слова в звуки. Этот последний шаг ничего не давал с точки зрения науки, но позволял убедительно продемонстрировать процесс обучения нервной сети, в котором мог поучаствовать каждый.
До обучения выход нейронной сети, как вы могли догадаться, представлял собой даже не словесную окрошку, а кашу из несвязанных фонем. После нескольких раундов обучения сеть начала выдавать нечто очень похожее на детский лепет: «Га, ба, та». Еще через несколько раундов она начала говорить словами, часто ошибаясь, но постепенно увеличивая количество правильно произнесенных слов. И наконец она заговорила почти на идеальном английском – правильно произнося не только выученные слова, но и любой текст. Самое поразительное, что нейросеть научилась этому, не зная никаких правил английского произношения, только посредством обучения на множестве примеров.
Интересно, что анализ нескольких скрытых слоев показал, что сеть знала даже некоторые словосочетания, хотя в ее архитектуре не были заложены правила английской речи. Создавалось впечатление, будто нейросеть училась говорить по-английски почти так же, как это делают в детстве носители английского языка. Несмотря на то, что мы, англоговорящие, не знаем (за исключением лингвистов) правил английского произношения, мы без особого труда и ошибок читаем вслух по-английски. Другими словами, при изучении английского языка нейронная сеть Сейновски вела себя так же, как человеческий мозг.
Все это делалось на компьютерах начала 1980-х гг. – медленных, как черепаха, по современным меркам. Сегодня компьютеры стали в десятки тысяч раз быстрее, а нейронные сети могут содержать сотни и даже тысячи скрытых слоев. Но, несмотря на возросшую сложность, в основе этих нейросетей лежит все тот же базовый принцип, который использовался Розенбергом, Сейновски, Хинтоном и Хеббом.
Говорящая нейронная сеть поразила не только меня. Сейновски стремительно взлетел на олимп научной славы (и остается там до сих пор). Он стал частым гостем на национальных телеканалах, а метод обратного распространения превратился в стандартный инструмент обучения нейросетей. Вскоре Терри перебрался из Университета Хопкинса в замечательный Институт биологических исследований Солка на побережье Южной Калифорнии, где работает по сей день.
Он по-прежнему носит темные костюмы и ездит на большом черном лимузине немецкого производства. В свои 70 с лишком лет он по-прежнему смеется громким кудахчущим смехом и, несмотря на многочисленные регалии и связанные с этим формальности, остается все тем же убергиком с неискоренимым налетом юношеского задора. Он любит хвастаться своими успехами в работе, но тут нет и тени самолюбования: Терри – скромный человек, который искренне увлечен наукой. Хотя налицо все предпосылки для черной профессиональной зависти, я не знаю никого, кто бы ни обожал Терри Сейновски.
Наверняка вы слышали о видящих компьютерах. Такие компьютеры умеют управлять беспилотными автомобилями и распознавать лица в толпе. Фантасты-паникеры любят рисовать страшное будущее, когда при входе в универмаг Macy’s компьютер будет по изображению с видеокамеры устанавливать вашу личность, изучать ваши покупательские предпочтения, после чего каким-то образом побуждать вас покупать больше товаров.
Могу вас успокоить, что на этот счет не стоит волноваться… пока не стоит. Помните, что капчи[28] все еще служат надежным средством защиты[29]. На самом деле капчи наглядно показывают пределы способностей современных компьютеров (конечно, компьютеры АНБ наверняка могут идентифицировать большинство капчей, но для обычных любительских ботов, пытающихся прорваться на обычные сайты, они не по зубам).
Как бы то ни было, уже сегодня видящие компьютеры удивляют нас своими возможностями – и они продолжают стремительно совершенствоваться. В качестве иллюстрации я расскажу вам о двух способах решения проблемы распознавания лиц, которая, как было сказано в начале этой книги, является Эверестом визуальной нейробиологии.
Лучшие компьютерные системы распознавания лиц сегодня действительно хорошо справляются с этой задачей. Они делают это почти так же хорошо, как и люди, хотя пока не могут сравниться с человеческим мозгом в компактности и энергоэффективности. Давайте рассмотрим два противоположных подхода. Первый – основанный на правилах, это означает, что он построен на выполнении серии строго заданных аналитических шагов. Такой подход обычно первым приходит в голову большинству людей (включая того самоуверенного аэрокосмического инженера, о котором я упомянул в начале главы). Для краткости мы будем называть основанный на правилах метод «глупым», хотя его варианты могут отличаться значительной сложностью.
Второй подход основан на машинном обучении и все больше начинает напоминать работу человеческого мозга. На данный момент кажется, что за этим подходом будущее. Именно он приводит в ужас защитников конфиденциальности. Назовем все версии на основе ИИ «умными» методами – потому что они имитируют работу нашего мозга, а я считаю мозг умной системой, – и дальше я сосредоточусь главным образом на них. На сегодняшний день именно умные методы доминируют в области распознавания лиц.
Задача алгоритма распознавания лиц состоит из двух основных шагов: сначала определить наличие лица, а затем установить, кому оно принадлежит. Первая задача называется
Но прежде, чем искать лица, компьютеру нужно подготовить изображение, сделать его максимально четким (для себя). Эти шаги, предшествующие запуску алгоритма обнаружения лиц, собирательно называются предварительной обработкой[30]. Существует множество разных способов улучшить четкость изображения, как это знает каждый, кому приходилось работать с Adobe Photoshop. Вот два примера. Во-первых, большинство естественных сцен имеют неравномерную освещенность: на открытом воздухе солнце создает тени и блики; в отделе мужской одежды Macy’s то же самое делает подсветка витрин. Благодаря особым свойствам нашего зрительного анализатора мы не замечаем различий в освещенности, чего нельзя сказать о цифровой камере в смартфоне или компьютере. Их педантичный цифровой анализатор воспринимает один и тот же по-разному освещенный объект как два разных объекта. Следовательно, первая операция по нормализации – «выравнивание» яркости. Компьютер вычисляет среднюю яркость всего изображения (иногда используя для этого мудреные средне-подобные величины) и затем корректирует яркость различных участков изображения так, как если бы вся сцена была равномерно освещена одинаковым источником света. Во-вторых, в большинстве случаев выполняется выделение краев, потому что, как мы уже не раз говорили, именно края несут основную информацию об объектах.
Подготовив изображение, компьютер может приступить к поиску лиц. Существует несколько способов это сделать. Один из наиболее любопытных, который отчасти копирует работу нейронных сетей в зрительной коре мозга, называется методом HOG (Histogram of Oriented Gradients), или гистограммой направленных градиентов.